

RAG Architecture: As the popularity of large language models (LLMs) continues to grow across industries, one of the recurring challenges remains: how to make their responses more accurate, context-aware, and up-to-date. These models are excellent at generating fluent text, but they often fall short when dealing with tasks that require specific or real-time knowledge.
That’s where Retrieval-Augmented Generation (RAG) comes into the picture. Instead of relying solely on what the model has memorized, RAG introduces a smarter way of working by integrating document retrieval into the generation process. This blog explores the concept of RAG architecture, how it works, where it’s useful, and how businesses can benefit from this emerging approach to working with language models.
Why Traditional LLMs Fall Short
LLMs like GPT, BERT, and others are pre-trained on vast datasets scraped from the internet. While this training gives them general knowledge, it also creates limitations:
1. Outdated Knowledge
- LLMs are frozen at the time of their last training data. They don’t know about recent developments unless explicitly retrained.
2. Factually Incorrect Responses
- They often generate content based on probability, not accuracy. This results in hallucinations plausible but incorrect information.
3. No Context of Your Business
- They don’t inherently know your documentation, internal FAQs, customer databases, or proprietary systems.
For industries like healthcare, finance, or law, relying on guesses or partial truths is not just risky it’s unacceptable.
What is Retrieval-Augmented Generation (RAG)?
RAG is an architectural design pattern that combines two critical parts:
- A Retriever, which searches for relevant documents or data.
- A Generator, which uses those documents to produce more accurate and grounded responses.
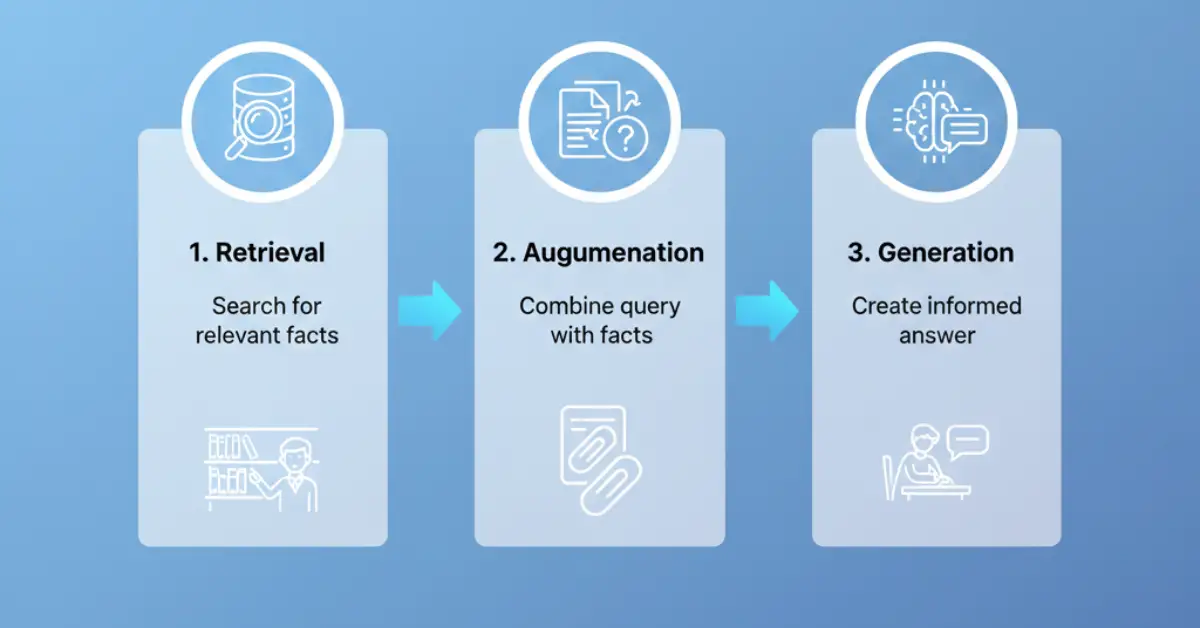
The key idea is simple: instead of answering from memory, the model first finds useful content, reads it, and then constructs a reply. This mimics how a human would respond by doing a quick search and then summarizing the findings.

How RAG Architecture Works
Here’s a simplified breakdown of how RAG functions in practice:
Step-by-Step Workflow:
- User Input: A question or prompt is submitted.
- Embedding Creation: The input is converted into a numerical vector using an embedding model.
- Document Retrieval: This vector is used to query a vector database, which returns the most relevant documents.
- Context Injection: The retrieved text is fed into the generator alongside the original prompt.
- Final Output: A response is produced that’s both contextually relevant and grounded in actual documents.
This dual system leads to more informed outputs and opens new possibilities for custom applications.
Key Technologies Behind RAG
To build a RAG system, several components are needed:
- Vector Databases: FAISS, Pinecone, Weaviate
- Embeddings: Open-source models or APIs to convert text into searchable vectors
- Orchestration Tools: LangChain, LlamaIndex
- Document Sources: Internal files, PDFs, knowledge bases, websites
These tools work together to store, retrieve, and apply information in real-time.
Benefits of Using RAG Architecture
Let’s look at some of the most compelling reasons why businesses are adopting RAG as a foundational strategy for language models:
More Accurate Responses
- Since the generator uses retrieved facts, it reduces the chance of hallucinations.
Domain-Specific Answers
- Businesses can feed their own data into the retrieval engine. The LLM can now answer based on internal documents, manuals, or records.
Fresh and Updatable Content
- The retrieval base can be updated anytime without retraining the model.
Greater Transparency
- Responses can include source citations, making them more trustworthy for both customers and regulators.
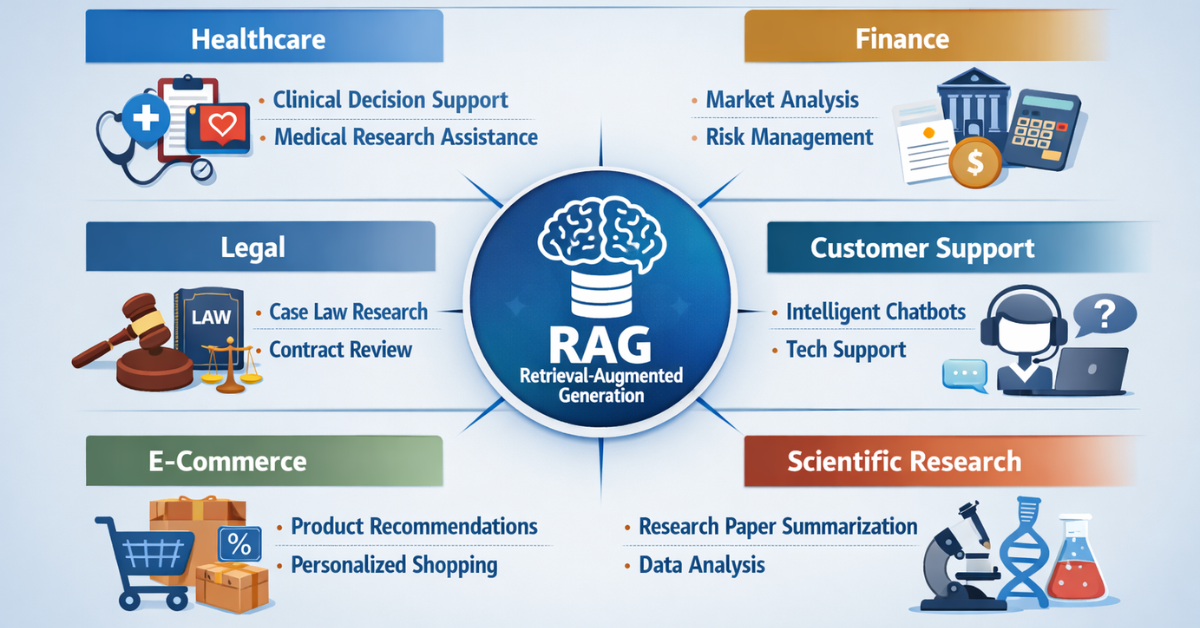
Industry Applications of RAG
The flexibility of RAG makes it applicable across multiple industries. Below are some of the most common examples:
Healthcare
- Use internal medical guidelines to answer patient queries or assist doctors during diagnosis.
Finance
- Generate investor summaries from quarterly earnings reports or compliance documents.
Retail
- Power customer support chatbots with real-time product availability and FAQ documents.
Legal
- Support legal research tools that reference specific regulations or precedent cases.
Education
- Provide tutoring or academic support based on a school’s internal curriculum or materials.
Common Challenges When Implementing RAG
While RAG offers clear benefits, there are some considerations to keep in mind.
Infrastructure Complexity
- Setting up and maintaining a vector database requires technical expertise and computing power.
Cost and Latency
- Retrieving documents and generating answers takes longer and uses more resources than a simple prompt-response model.
Quality Control
- If the document base contains outdated, irrelevant, or poor-quality information, the output suffers.
These challenges are manageable, especially with the right architecture design and implementation partner.
Why RAG is Gaining Momentum
There’s a reason why many AI-forward businesses are now experimenting with or deploying RAG-based systems. It provides a pathway to move beyond generic responses and build tools that actually understand your business.
- It reduces the risk of inaccuracies in sensitive areas.
- It allows companies to control and shape the knowledge their systems use.
- It improves user experience by grounding responses in verifiable sources.
Instead of relying on a model trained on the public internet, businesses can now build systems that rely on their own expertise and data.
How Miniml Builds Custom RAG Solutions
At Miniml, we work with businesses to make intelligent use of their existing data using large language models enhanced by retrieval.
What We Offer:
- Custom Language Model Workflows: We assess your use case and select the right combination of retrieval and generation models.
- End-to-End Setup: From data cleaning and vectorization to infrastructure and API deployment.
- Compliance-Ready Solutions: Designed for industries that deal with confidential or regulated data.
We don’t believe in a one-size-fits-all solution. Every RAG implementation is tailored to match your business goals and technical environment.
Final Thoughts
RAG architecture is a simple yet powerful idea retrieve relevant data first, then generate informed responses. As LLMs become more deeply integrated into customer service, analytics, and automation, businesses are realizing the value of smarter, grounded outputs.
If your current chatbot or content system struggles with accuracy or context, now might be the time to explore Retrieval-Augmented Generation. At Miniml, we help businesses in healthcare, finance, retail, and education move toward systems that work smarter, not just harder.