

The AI community loves a good debate, and few topics have sparked more discussion than whether Retrieval Augmented Generation has become obsolete. With models like Gemini 2.5 Pro processing up to 1 million tokens and Claude handling 200K tokens, some declared RAG dead on arrival.
But here’s the truth: Reports of RAG’s death have been greatly exaggerated. At Miniml, we’ve watched this debate unfold while helping businesses navigate the real decision they face. Should you build complex retrieval pipelines, or simply load your entire knowledge base into an expanding context window?
Understanding Retrieval Augmented Generation (RAG)
RAG emerged as a solution to a core limitation of large language models. LLMs cannot access information beyond their training cutoff, and they certainly cannot tap into your proprietary business data or internal documentation.
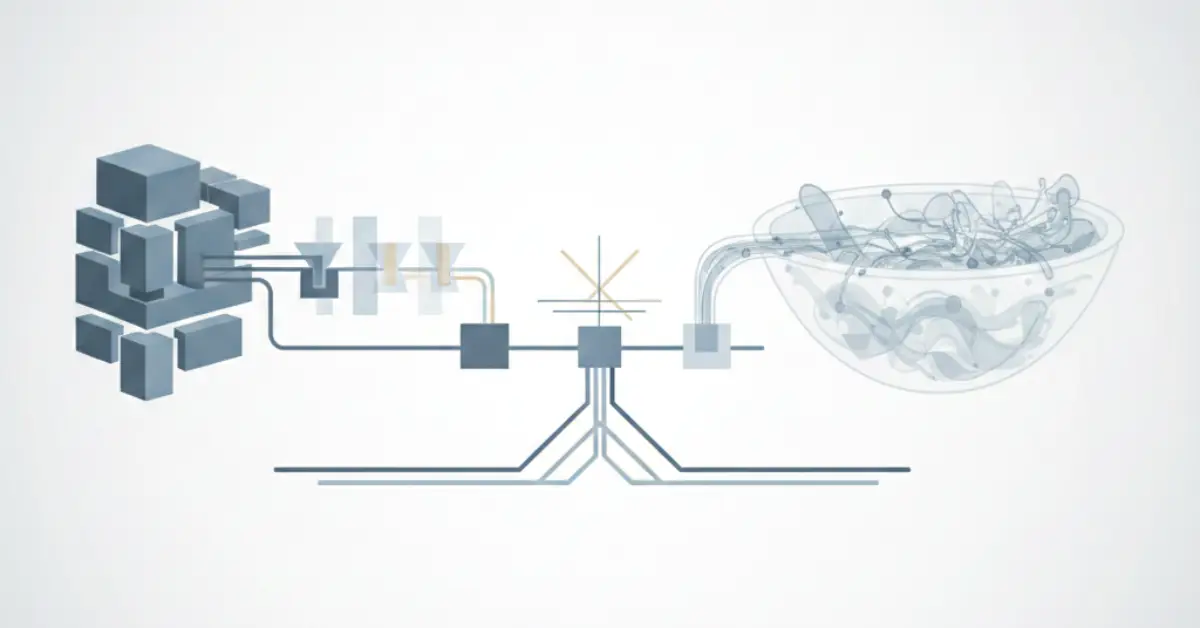
RAG solves this by adding a retrieval layer before generation. When a user submits a query, the system searches your knowledge base for relevant documents, then injects that context into the prompt for grounded responses.
A typical RAG pipeline includes:
- Document Processing: Breaking large documents into smaller, manageable chunks
- Embedding Generation: Converting text into numerical vectors that capture semantic meaning
- Vector Storage: Storing embeddings in databases designed for similarity search
- Retrieval and Reranking: Finding and prioritizing the most relevant information
- Generation: Feeding retrieved context to an LLM for final response creation
The Rise of Long-Context Windows
When GPT-3.5 launched in late 2022, its context window was limited to roughly 4,096 tokens, about six pages of text. This constraint made RAG essential for any serious knowledge application.
The landscape in 2025 looks dramatically different. Modern models offer context windows that seemed impossible just two years ago:
- GPT-4.1 supports 128K tokens
- Claude handles 200K tokens with high accuracy
- Gemini 2.5 Pro processes up to 1 million tokens (approximately 3,000 pages)
The appeal is obvious. Instead of building retrieval infrastructure, you load everything into context and let the model determine relevance. No chunking strategies, no embedding models, no vector databases to maintain.
The Real Cost Comparison
Before declaring a winner, Miniml recommends examining what each approach actually costs in practice. Research from LightOn indicates that RAG can be 8 to 82 times cheaper than long-context approaches for typical enterprise workloads.
Consider a customer support application handling 1,000 queries daily. Processing 100K tokens per query at current API pricing could cost thousands monthly. The same application using RAG might retrieve just 2,000 to 5,000 relevant tokens per query, cutting expenses dramatically.
RAG infrastructure requires upfront investment:
- Vector database hosting and maintenance
- Embedding model API calls or self-hosted systems
- Reranker models for improved relevance
- Development time for pipeline optimization
However, operational costs per query remain significantly lower than processing massive context windows at scale.
Performance: Where Each Approach Excels
Research from Salesforce AI highlights a critical weakness in long-context models called the “lost in the middle” problem. When relevant information sits buried in lengthy context, models often struggle to retrieve it accurately.
RAG sidesteps this issue by surfacing only the most relevant information within a much smaller context window. Studies consistently show RAG outperforms long-context approaches on citation accuracy.
Key performance differences include:
- Latency: RAG delivers faster responses by processing smaller chunks
- Dynamic Updates: New documents can be indexed immediately without reprocessing entire contexts
- Source Attribution: RAG provides clear traceability back to original documents
When to Use Long-Context Windows
Long-context models work well in specific scenarios. Miniml typically recommends this approach for one-off analysis tasks, small static datasets, or situations where development speed matters more than operational efficiency.
Long-context windows suit these use cases:
- Analyzing single lengthy documents like contracts or reports
- Processing entire codebases where file connections matter
- Prototyping and rapid development phases
- Working with limited document sets that rarely change
When RAG Remains the Better Choice
RAG continues to dominate enterprise deployments for solid reasons. The approach handles scale, cost sensitivity, and compliance requirements that long-context windows struggle to match.
RAG excels in these situations:
- Large knowledge bases exceeding practical context limits
- High-volume applications where per-query costs matter
- Regulated industries requiring clear source attribution
- Multi-source retrieval from diverse databases and APIs
- Frequently updated content with regular additions
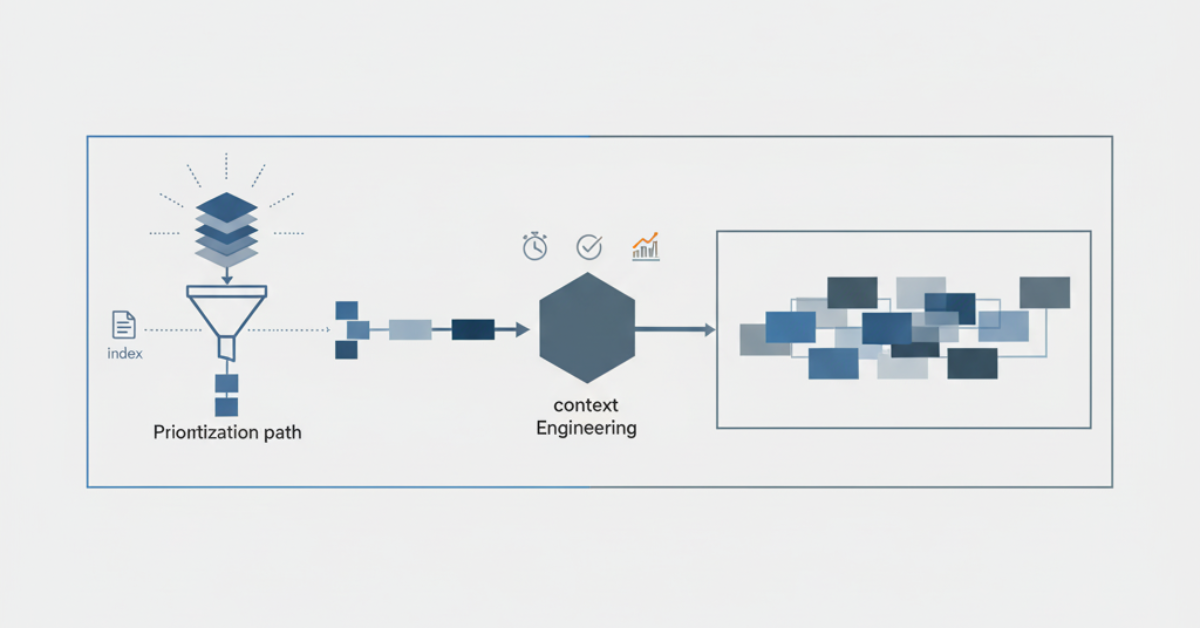
The Hybrid Future: Context Engineering
The most sophisticated AI systems in 2025 don’t choose between RAG and long-context. They combine both approaches through what practitioners now call context engineering.
This approach treats context window management as a first-class concern. Rather than blindly retrieving or loading everything into context, modern systems make intelligent decisions about whether retrieval is needed, what sources to query, and how to structure the final prompt.
Context engineering considers:
- Whether retrieval is necessary for each specific query
- Which sources provide the most relevant information
- How much context to include without overwhelming the model
- When to compress or summarize information
Making the Right Choice for Your Business
Selecting between RAG and long-context windows requires understanding your business requirements, growth plans, and operational constraints. At Miniml, we guide clients through this decision by examining their specific circumstances.
Start by asking these questions:
- How large is your knowledge base, and how fast is it growing?
- What query volume do you anticipate handling?
- How critical is source attribution for compliance purposes?
- What latency can your users tolerate?
- Do you have engineering resources to build retrieval infrastructure?
For many enterprises, the answer involves elements of both approaches, deployed strategically based on specific use cases.
Conclusion
RAG is not dead. It has evolved. The simple retrieve-and-generate pipelines of 2023 are giving way to sophisticated context engineering systems that use the strengths of both retrieval and expanded context windows.
The question isn’t which technology wins. It’s which combination delivers the best results for your specific needs. Whether you’re building customer-facing AI applications or internal knowledge systems, choosing the right approach requires deep expertise in both technologies.
Miniml helps businesses navigate these architectural decisions with clarity, ensuring your AI investments deliver real value rather than following industry hype.